PDF OCR is one of the most important technologies used in modern document management systems. It allows users to convert scanned PDF files, image-based documents, and printed papers into editable and searchable digital files.
Businesses, students, accountants, researchers, and office professionals use PDF OCR tools to extract text, tables, and spreadsheet data from scanned documents quickly and accurately.
In this beginner-friendly guide, you will learn what PDF OCR is, how it works, its benefits, common uses, and why AI-powered OCR technology is becoming essential for modern workflows.
What is PDF OCR?
PDF OCR stands for Optical Character Recognition for PDF files.
It is a technology that allows software to recognize:
- Text
- Numbers
- Tables
- Spreadsheet structures
from scanned or image-based PDF documents.
OCR converts non-editable PDF content into machine-readable and editable text.
For example, PDF OCR can convert:
- Scanned invoices
- Printed reports
- Receipts
- Bank statements
- Research papers
- Screenshot PDFs
into editable formats such as:
- Excel
- Word
- TXT
- Searchable PDFs
You may also like:
“What is OCR Technology?”
Why PDF OCR is Important
Many PDF files are created using scanners or cameras. These PDFs are basically images, not editable documents.
Without OCR:
- Text cannot be selected
- Data cannot be copied easily
- Tables cannot be edited
- Search functions do not work properly
PDF OCR solves these problems by extracting the hidden text from scanned documents.
This helps users:
- Save time
- Reduce manual work
- Improve productivity
- Organize documents efficiently
Types of PDF Files
Understanding PDF types is important before learning OCR.
1. Editable PDFs
Editable PDFs already contain selectable text.
These files usually:
- Allow copy and paste
- Support text search
- Do not require OCR
2. Scanned PDFs
Scanned PDFs are image-based documents.
These files:
- Cannot be edited directly
- Require OCR technology
- Store content as images
OCR is essential for extracting data from scanned PDFs.
Related guide:
“Convert Scanned PDF to Editable Excel”
How PDF OCR Works
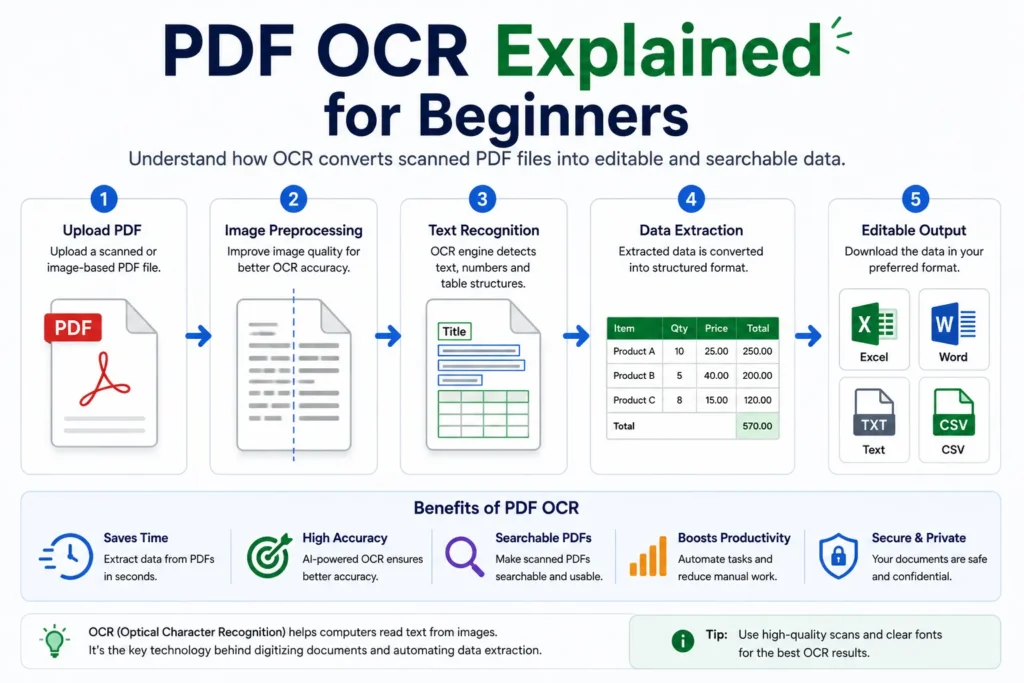
PDF OCR systems follow multiple processing steps to convert scanned documents into editable data.
Step 1: PDF Upload
The user uploads a scanned or image-based PDF file.
Supported files may include:
- Scanned reports
- Invoice PDFs
- Receipt scans
- Screenshot PDFs
Step 2: Image Preprocessing
Before text recognition begins, the OCR system improves image quality.
This may include:
- Noise removal
- Brightness adjustment
- Contrast enhancement
- Deskewing tilted pages
- Sharpening blurry text
Better image quality improves OCR accuracy significantly.
Step 3: Text Detection
The OCR engine scans the document and identifies:
- Characters
- Words
- Numbers
- Tables
- Spreadsheet layouts
Modern AI-powered OCR tools can also detect:
- Rows
- Columns
- Table borders
- Document structure
Step 4: Character Recognition
The OCR engine compares detected characters with stored language patterns and machine learning models.
It identifies:
- Letters
- Numbers
- Symbols
- Spreadsheet values
AI-powered OCR systems can recognize multiple languages and fonts.
Step 5: Editable Output Generation
After processing is complete, the OCR system generates editable files such as:
- Excel spreadsheets
- Word documents
- TXT files
- Searchable PDFs
Users can then edit, search, copy, and organize the extracted content easily.
AI OCR vs Traditional OCR
Modern OCR tools now use artificial intelligence and machine learning.
Traditional OCR
Traditional OCR works by matching character shapes with predefined patterns.
It works well for:
- Printed text
- Simple documents
- High-quality scans
However, it struggles with:
- Handwriting
- Complex layouts
- Poor-quality images
AI-Powered OCR
AI-based OCR systems understand:
- Table structures
- Layout patterns
- Handwriting styles
- Spreadsheet formatting
AI OCR provides:
- Better accuracy
- Faster processing
- Improved formatting retention
- Smarter document analysis
You may also read:
“Best AI Tools for Image to Excel Conversion”
Common Uses of PDF OCR
PDF OCR technology is widely used for:
- Invoice processing
- Accounting
- Tax management
- Research work
- Legal documents
- Business reports
- Data entry automation
- Spreadsheet extraction
Businesses use OCR automation to reduce repetitive manual tasks.
Advantages of PDF OCR
Saves Time
Large scanned documents can be processed within seconds.
Reduces Manual Data Entry
Users no longer need to type information manually.
Makes PDFs Searchable
OCR allows users to search text inside scanned documents.
Improves Productivity
Businesses can automate document workflows efficiently.
Better Data Organization
Extracted information can be stored and managed easily.
Challenges of PDF OCR
Although OCR technology is powerful, some limitations still exist.
Poor Scan Quality
Blurry or low-resolution PDFs reduce OCR accuracy.
Handwritten Text
Some handwriting styles remain difficult to recognize.
Complex Tables
Merged cells and unusual layouts may confuse OCR systems.
Multi-Language Documents
Certain OCR tools may have limited language support.
Tips for Better OCR Accuracy
To improve PDF OCR results:
- Use high-resolution scans
- Keep pages properly aligned
- Avoid blurry images
- Use readable fonts
- Choose AI-powered OCR tools
These simple improvements can significantly improve OCR performance.
OCR vs Manual Data Extraction
| Feature | OCR Technology | Manual Extraction |
|---|---|---|
| Speed | Very Fast | Slow |
| Accuracy | High | Depends on user |
| Productivity | Better | Limited |
| Scalability | Easy | Difficult |
| Time Required | Seconds | Hours |
AI-powered OCR clearly provides a faster and more efficient solution for document processing.
You may also like:
“How to Extract Data from PDF Files”
Future of PDF OCR Technology
Artificial intelligence is rapidly improving OCR systems and document automation.
Future OCR tools may provide:
- Better handwriting recognition
- Real-time document analysis
- Smarter table extraction
- Improved multilingual support
- Higher formatting accuracy
AI-powered document automation will continue transforming modern business workflows and data management systems.
Related article:
“Future of AI in Document Management”
Conclusion
PDF OCR technology allows users to convert scanned and image-based PDF documents into editable and searchable files quickly and accurately.
Using OCR and AI-powered systems, users can extract text, tables, spreadsheet data, and structured information from PDFs without manual typing.
Whether you are handling invoices, reports, research papers, or business records, PDF OCR tools provide a fast, efficient, and reliable solution for modern document processing and workflow automation.